Amazon Glacier#
About Glacier : It is an online file storage web service that provides storage for data archiving and backup. (for more info : https://docs.aws.amazon.com/glacier/index.html#lang/en_us
 ) You need to download this jar file and place it in your CrushFTP ▸ plugins ▸ lib folder. aws-java-sdk.jar
) You need to download this jar file and place it in your CrushFTP ▸ plugins ▸ lib folder. aws-java-sdk.jar
The url should looks like (Replace the url with your corresponding data!):
glacier://{ACCESS_KEY_ID}:{SECRET_KEY_ID}@glacier.{REGION}.amazonaws.com/
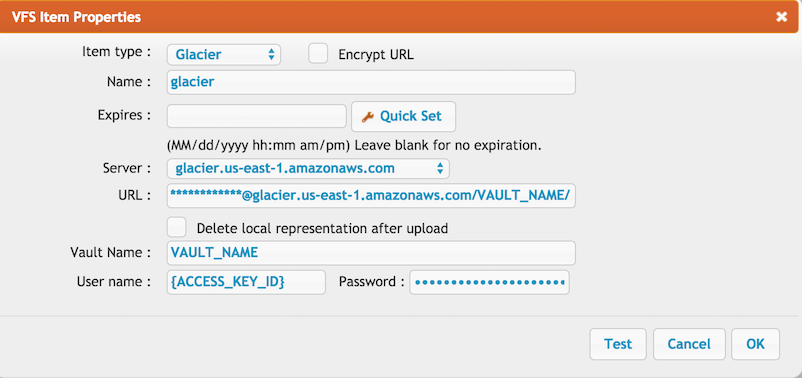
Select the proper region form the Server combobox. The default region is : us-east-1
It will list all the vaults. Upload is only allowed under a vault folder. We hold a special "glacier" folder on the CrushFTP server which has the folder structure simulated, and "file" items which are XML pointers to the real glacier archive data. Each archive will have the following archive description:
<m><v>4</v><p>[Base64 encoded path]</p><lm>[the current date]</lm></m>You can turn off xml reference store by checking the "Delete local representation after upload" flag. It will delete the xml pointer 1 second after the upload.
Glacier task#
If you have archives on glacier not managed by CrusFTP, you can create CrushFTP simulated folder and file(XML pointers to your archive data) structure by this task.
It requires two step as it first creates an Amazone job, and it will download the result, once the job is finished (usually it requires 3-5 hour to finish the job), then based on the result will create the folder structure and XML pointers.(for more info : https://docs.aws.amazon.com/amazonglacier/latest/dev/vault-inventory.html
)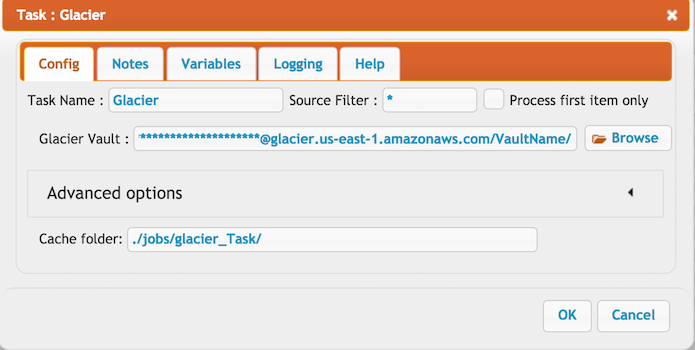
The Crush job needs to be run at least twice:
1. It creates the Amazon job. The Amazon job id will be stored in glacier_info.XML file located at Cache folder (By default it points to the CrushFTP job folder see at task settings)
<?xml version="1.0" encoding="UTF-8"?>
<GlacierTask type="properties">
<job_id>Amazon job id</job_id>
</GlacierTask>
2. It checks the Amazon job status, and download the inventory when the Amazon job is finished.If the glacier_info.XML exist, based on the Amazon job's id checks the result of the job, you can notify the job result using an email task after the glacier task with Amazon job status variable(values : In progress, Failed, Succeeded):
{glacier_job_satus}
Add new attachment
Only authorized users are allowed to upload new attachments.
List of attachments
| Kind | Attachment Name | Size | Version | Date Modified | Author | Change note |
|---|---|---|---|---|---|---|
jar |
aws-java-sdk.jar | 101,552.5 kB | 1 | 29-Dec-2020 05:25 | krivacsz | |
png |
glacier_task.png | 88.7 kB | 1 | 29-Dec-2020 05:25 | krivacsz | |
png |
glacier_vfs.png | 110.7 kB | 4 | 29-Dec-2020 05:25 | krivacsz |
{kind=link}
{kind=link}
«
This particular version was published on 29-Dec-2020 05:25 by krivacsz.
G’day (anonymous guest)
Log in
CrushFTP10 | What's New
- WebInterface
- Server Admin
- User Manager
- Client Apps
- CrushBalance Load Balancer
- High Availability
- Self Registration
- Preferences
- Email Templates
- Restrictions
- Replication
- Banning
- Logging
- Encryption
- Alerts
- Folder Monitor
- Tunnels
- Syncs
- User Config
- Search Config
- Preview
- Misc
- Plugins
- FAQ
- API
- Linux Install
- Virtual Linux Server
- Server Variables
- Google Authenticator and Microsoft Authenticator
JSPWiki