Add new attachment
Only authorized users are allowed to upload new attachments.
List of attachments
| Kind | Attachment Name | Size | Version | Date Modified | Author | Change note |
|---|---|---|---|---|---|---|
jar |
aws-java-sdk.jar | 101,552.5 kB | 1 | 05-Dec-2023 05:32 | krivacsz | |
png |
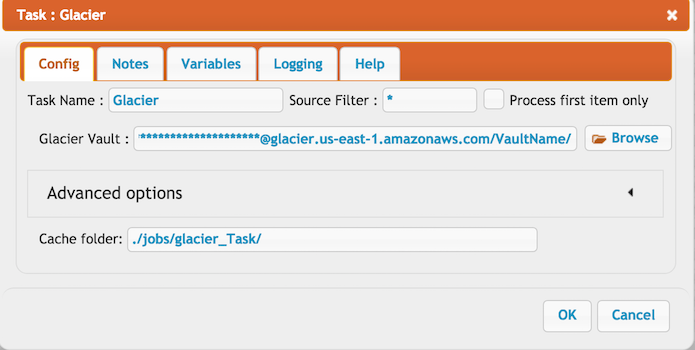
glacier_task.png | 88.7 kB | 1 | 05-Dec-2023 05:32 | krivacsz | |
png |
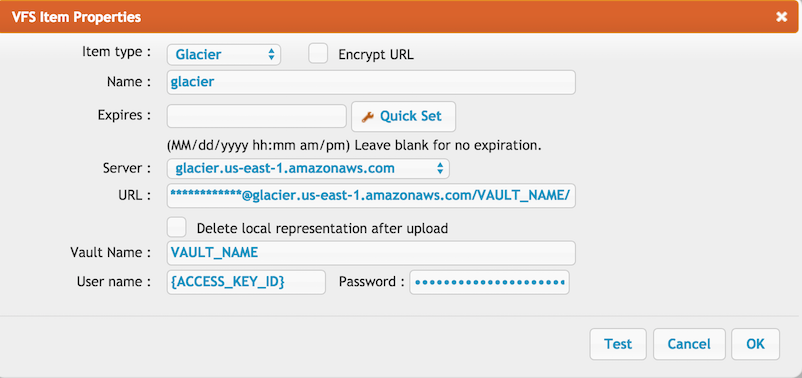
glacier_vfs.png | 110.7 kB | 4 | 05-Dec-2023 05:32 | krivacsz |
This page (revision-86) was last changed on 09-Jun-2025 03:19 by krivacsz
This page was created on 05-Dec-2023 05:32 by krivacsz
Only authorized users are allowed to rename pages.
Only authorized users are allowed to delete pages.
Incoming links
Glacier Integration ...nobodyOutgoing links
| Version | Date Modified | Size | Author | Changes ... | Change note |
|---|---|---|---|---|---|
| 86 | 09-Jun-2025 03:19 | 4.586 kB | krivacsz | to previous | |
| 85 | 22-May-2025 03:06 | 4.581 kB | krivacsz | to previous | to last | |
| 84 | 22-May-2025 03:05 | 4.479 kB | krivacsz | to previous | to last | |
| 83 | 22-May-2025 03:03 | 4.437 kB | krivacsz | to previous | to last | |
| 82 | 22-May-2025 03:00 | 4.429 kB | krivacsz | to previous | to last | |
| 81 | 22-May-2025 03:00 | 4.415 kB | krivacsz | to previous | to last |
«
This page (revision-86) was last changed on 09-Jun-2025 03:19 by krivacsz
G’day (anonymous guest)
Log in
CrushFTP11 | What's New

{kind=link}
{kind=link}
{kind=link}
{kind=link}
- WebInterface
- Server Admin
- User Manager
- Client Apps
- CrushBalance Load Balancer
- High Availability
- Self Registration
- Preferences
- Email Templates
- Restrictions
- Replication
- Banning
- Logging
- Encryption
- Alerts
- Folder Monitor
- Tunnels
- Syncs
- User Config
- Search Config
- Preview
- Misc
- Plugins
- Manage Shares
- PGP
- Telnet
- FAQ
- API
- Linux Install
- Virtual Linux Server
- Server Variables
- Google Authenticator and Microsoft Authenticator
- AS2 EDI
JSPWiki