| At line 1 removed one line |
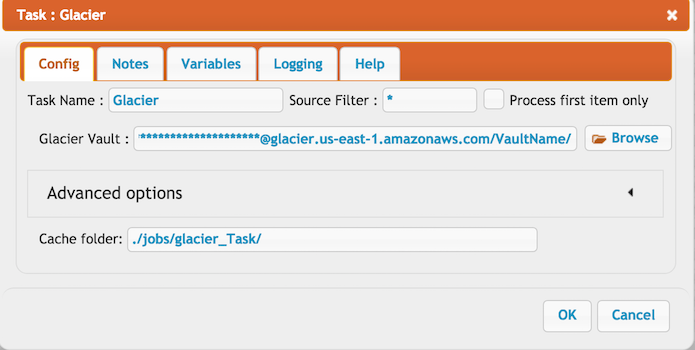
| !!Amazon Glacier |
| At line 3 changed one line |
| About Glacier : It is an online file storage web service that provides storage for data archiving and backup. (for more info : [https://docs.aws.amazon.com/glacier/index.html#lang/en_us]) You need to download this jar file and place it in your CrushFTP ▸ plugins ▸ lib folder. [aws-java-sdk.jar]\\ |
| !!Amazon Glacier Integration\\ |
| At line 5 changed one line |
| The url should looks like (Replace the url with your corresponding data!):\\ |
| Amazon Glacier is a cloud-based storage service designed for long-term data archiving and backup. It offers secure, durable, and low-cost storage for infrequently accessed data. For more information, visit: [Amazon Glacier Link|https://docs.aws.amazon.com/glacier/index.html#lang/en_us].\\ |
| ---- |
| __⚠️ Important__: Dependency jar files must be downloaded and placed in your __CrushFTP Install Folder/plugins/ lib__. ⚠️ Restart is required to load the new Glacier dependency jar. [ Download Link|aws-java-sdk.jar]\\ |
| ---- |
| __⚠️ Proxy Configuration__: If your server accesses the internet through a proxy, make sure that the required Glacier domains are whitelisted.\\ |
| ---- |
| \\ |
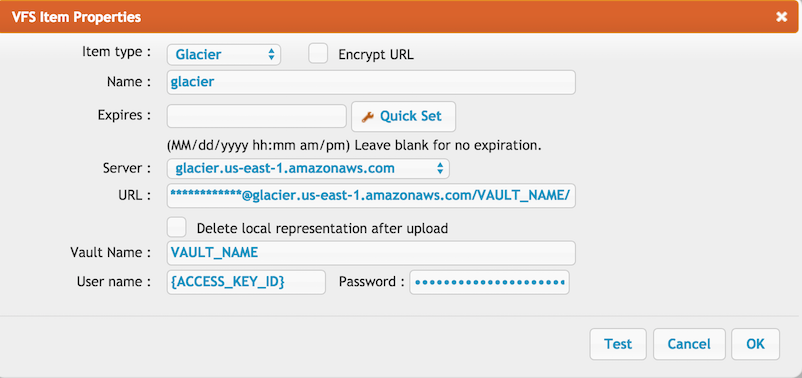
| The __URL__ should look like this (replace the placeholders with your actual values):\\ |
| At line 8 changed one line |
| }}} |
| }}}\\ |
| Make sure to insert your Access Key, Secret key, and AWS region to form a valid connection URL for Glacier.\\ |
| At line 12 changed 2 lines |
| Select the proper region form the Server combobox. The default region is : [us-east-1]\\ |
| It will list all the vaults. Upload is only allowed under a vault folder. We hold a special "glacier" folder on the CrushFTP server which has the folder structure simulated, and "file" items which are XML pointers to the real glacier archive data. Each archive will have the following archive description:\\ |
| Select the appropriate region from the Server dropdown menu. The default region is __us-east-1__.\\ |
| Enter the Vault Name in the corresponding field. If you leave it empty, the system will automatically list all available Vaults in the selected region. Note that uploads are only allowed inside a Vault folder.\\ |
| CrushFTP uses a special __glacier__ folder to simulate the folder structure. Files uploaded here are represented as XML pointers referencing the actual archive in Glacier. Each archive includes a description in this format:\\ |
| At line 16 changed 2 lines |
| }}} |
| You can turn off the xml reference store by checking the "Delete local representation after upload" flag. It will delete the xml pointer one second after the upload.\\ |
| }}}\\ |
| At line 26 added 3 lines |
| You can turn off the XML reference storage by enabling the __Delete local representation after upload__ option.\\\ |
| When this is checked, the XML pointer file will be automatically deleted one second after the upload, leaving only the archived data in Glacier.\\\ |
| \\ |
| At line 21 changed 2 lines |
| If you already have archives on glacier not managed by CrusFTP, you can create CrushFTP simulated folder and file(XML pointers to your archive data) structure by this task.\\ |
| It requires two step as it first creates an Amazon job, and it will download the glacier inventory result, once the Amazon job is finished (usually it requires 3-5 hour to be finished), then based on the downloaded inventory will create the CrushFTP's simulated structures.(for more info : [https://docs.aws.amazon.com/amazonglacier/latest/dev/vault-inventory.html])\\ |
| If you already have archives in Glacier that were ⚠️ __not uploaded through CrushFTP__, you can use this task to rebuild the simulated folder and file structure (XML Pointers) that CrushFTP uses.\\ |
| This process happens in two steps: first, it creates an Amazon Glacier Inventory retrieval job. Once this job is completed (typically in 3–5 hours), it downloads the inventory and uses it to generate CrushFTP’s simulated folder structure and file references.\\ |
| For more details, see: [Amazon Valult Inventory Link|https://docs.aws.amazon.com/amazonglacier/latest/dev/vault-inventory.html]\\ |
| At line 26 changed one line |
| The Crush job needs to be run at least twice:\\ |
| __⚠️ Important__: The CrushTask must be run at __least twice__:\\ |
| At line 28 changed one line |
| 1. It creates the Amazon job. The Amazon job id will be stored in [glacier_info.XML] file located at Cache folder (By default it points to the CrushFTP job folder see at task settings)\\ |
| __The first run__: It creates the Amazon inventory job, and the job ID returned by Amazon will be stored in the __glacier_info.XML__ file located in the Cache folder.\\ |
| By default, this Cache folder points to the CrushFTP job folder, which can be found or customized in the task settings. This file is used later to track and complete the inventory retrieval process.\\ |
| At line 34 changed 3 lines |
| }}} |
| 2. It checks the Amazon job status, and download the inventory when the Amazon job is finished.\\ |
| If the [glacier_info.XML] exist, based on the Amazon job's id checks the result of the job, you can notify the job result using an email task after the glacier task with Amazon job status variable(values : In progress, Failed, Succeeded): |
| }}}\\ |
| \\ |
| __The second run__: It checks the status of the Amazon job and downloads the inventory once the job is finished. If the __glacier_info.XML__ file exists, the task uses the stored __Amazon job ID__ to check the current status of the job.\\ |
| You can set up an __Email task__ after the Glacier task to notify the job result, using the Amazon job status variable.\\ |
| Possible values for the job status are: __In progress__, __Failed__, or __Succeeded__.\\ |
| \\__ |
| At line 39 changed 3 lines |
| }}} |
| Once the Amazon job status is Succeeded, it downloads the glacier vault inventory and creates the CrushFTP's glacier folder and file(XML pointers to your archive data) structures based on glacier inventory. |
| The archive description should have the following format: |
| }}}\\ |
| \\ |
| Once the Amazon job status is Succeeded, the task will download the Glacier Vault Inventory and use it to create CrushFTP’s simulated glacier folder and file structure. These files act as XML pointers referencing your archived data in Glacier.\\ |
| Each archive entry will include a description in the following format:\\ |
| At line 44 changed 2 lines |
| }}} |
| If your glacier archive descriptions does not have the format like above, it will creates just the XML pointers with archive description as file name. |
| }}}\\ |
| This structure allows CrushFTP to represent your Glacier archives in a way that mimics a traditional folder and file system.\\ |
| \\ |
| __⚠️ Note__: If your Glacier archive descriptions do not follow the required format, CrushFTP will still create the XML pointers, but it will use the archive description as the file name instead of placing the file in a simulated folder structure.\\ |
| This means the files will appear flat (without folders), named directly after the description stored with each archive.\\\ |
| \\ |

{kind=link}
{kind=link}
{kind=link}
{kind=link}